Retrieval-Augmented Generation (RAG) pipelines are changing the game. They blend information retrieval with generative models. The result? Smarter, context-aware responses.
As an AI development company, we at The Brihaspati Infotech leverage RAG to build smart, high-impact solutions. Think chatbots that actually understand you. Research tools that don’t hallucinate.
This guide breaks it down. It brings a practical roadmap to build RAG pipelines. Whether you’re leveling up your AI stack or looking to hire a Python developer, this will help you move fast and efficiently.
What is Retrieval Augmented Generation (RAG)?
RAG is where search meets smarts. It combines information retrieval with generative AI. It first pulls relevant data from a knowledge base using a query. The pulled data is then fed into a language model to generate correct and context-oriented responses. It’s analogous to combining smart search with AI writing—fast, relevant, and intelligent.
Why RAG Matters for Your AI Projects?
- Accuracy: Responses are grounded in real data, cutting down guesswork.
- Context-Aware: Answers adapt intelligently to user queries and your app’s logic.
- Scalable: Designed to handle large datasets efficiently, perfect for growing applications.
- Cost-Efficient: Minimizes constant retraining, keeping your AI lean and effective.
To bring these benefits to life, you need a structured system—this is where RAG pipelines come in.
What is a RAG pipeline?
Retrieval-Augmented Generation (RAG) pipelines merge information retrieval with generative AI to deliver precise, context-rich responses. They fetch relevant documents and feed them to a generative model for smarter outputs.
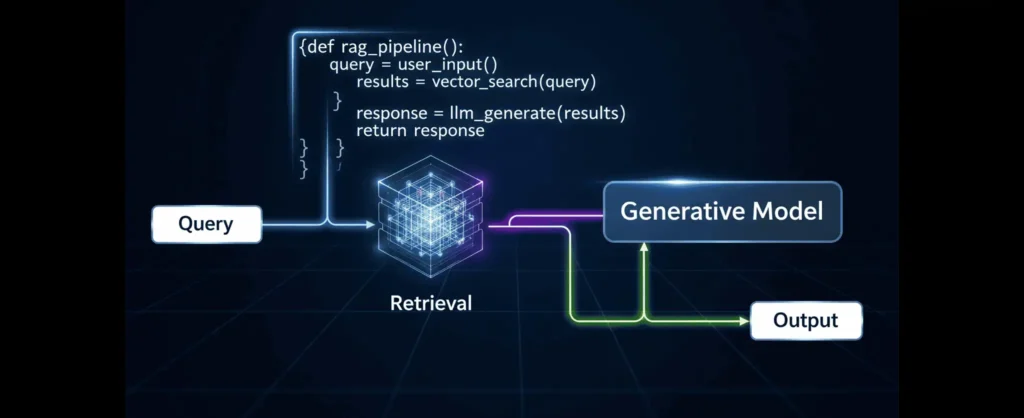
Key Components
- Retrieval System: Think of this as the AI’s “search engine.” It quickly scans through tons of data using techniques like vector search or document indexing to find exactly what’s relevant.
- Generative Model: After the retrieval step, this is the brain that puts everything together. Models like GPT or LLaMA take the info and create a natural, human-like response.
Use Cases of RAG Pipelines
- Question answering systems that actually know the facts.
- Build a Chatbot using RAG that gets you — no more generic or off-topic replies.
- Knowledge bases that can summarize and explain on the fly.
- Research assistants who help dig through piles of data in real time.
Benefits of RAG Pipelines
- Better accuracy, since answers are grounded in real data.
- Less “AI making stuff up” (less hallucinations).
- Answers that fit the exact context of your question.
Challenges
- Scaling up can get tricky when you have lots of data or users.
- Latency concerns as retrieval and generation sometimes take a good time.
- Data Quality: If the source is junk, the output won’t shine.
If you want a RAG pipeline that’s tailored to your business and scales with your data, hire AI developers who know how to integrate retrieval systems, vector databases, and generative models seamlessly.
Architecture of RAG Pipelines
Putting together a RAG pipeline is like assembling a well-oiled machine — each part plays its role to help your AI fetch relevant information and generate smart responses. Here’s a closer look at each core component and its role in the pipeline.
Data Ingestion and Preprocessing
First, your data is ingested. Whether it’s PDFs, web pages, or databases, raw data usually isn’t ready to go right out of the gate. It needs to be extracted, cleaned up, and chopped into bite-sized pieces so the system can digest it easily.
Document Indexing of RAG Pipelines
Next up, those text chunks get turned into embeddings — think of these as numerical summaries that capture the meaning of the text. We usually use models like sentence transformers or BERT for this. Then, these embeddings get stored in vector databases like Pinecone, FAISS, or Weaviate to make future searches super fast.
Retrieval System
When someone asks a question, the system turns their query into an embedding too. It then runs a similarity search using tricks like cosine similarity or nearest neighbors — to pull out the most relevant documents from the database.
Generative Model
Here’s where the magic happens. The AI takes those retrieved documents and feeds them into a large language model (LLM) like OpenAI, Google Gemini, or your own custom model. The LLM then cooks up a clear, relevant answer based on the info it found.
Post-Processing and Output
The system presents a refined response with nice formatting or even ranking when there are multiple responses. They handle tricky cases well that have no relevant response by providing fallback answers.
RAG Pipelines Workflow
A RAG (Retrieval-Augmented Generation) workflow combines information retrieval with AI text generation to deliver accurate, context-rich responses.
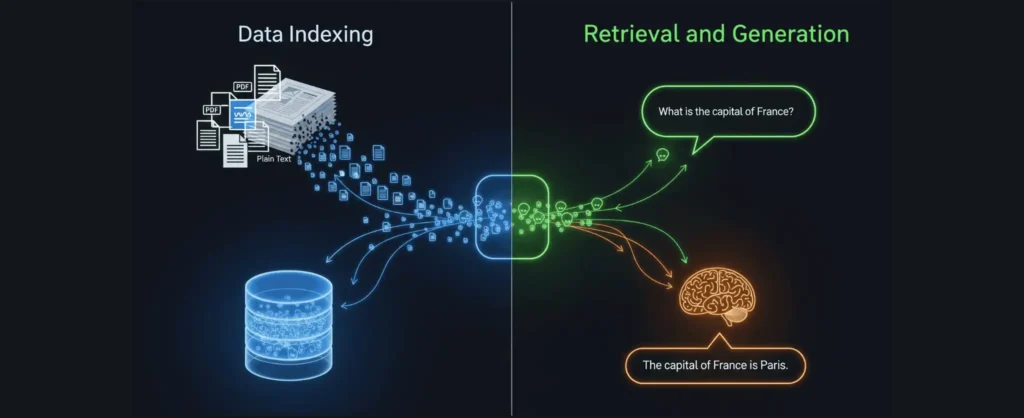
Implementing a well-structured RAG workflow can significantly boost the accuracy and relevance of your AI solutions.
Ready to bring it to life? Hire expert Python developers today and build your next-gen AI pipeline.
What Are the Best Tools for Building RAG Pipelines?
When it comes to building a RAG pipeline, having the right tools can make all the difference. Here’s a quick tour of some of the best options out there for each stage of the process.
Data Preprocessing and Ingestion
Before your AI can do its magic, the data needs some TLC: cleaning, chopping, and prepping. These tools will help you get that done smoothly:
| Tools | Pros | Cons | Best for |
|---|---|---|---|
| Pandas, NLTK, spaCy | Great for cleaning and prepping text data | Requires coding, some learning curve | Handling raw text from PDFs, websites, databases |
| PyPDF2, BeautifulSoup, Scrapy | Efficient extraction from PDFs and web scraping | Can get complex with dynamic sites | Extracting text from various data sources |
Embedding Generation
To get your text into a format the AI understands, you need embeddings — think of them as the AI’s secret decoder ring. Here’s what’s popular:
| Tools | Pros | Cons | Best for |
|---|---|---|---|
| Sentence Transformers (all-MiniLM) | Fast, high-quality embeddings | Some setup needed | Converting text into vector form |
| Hugging Face Transformers | Large variety of models | Can be heavy to fine-tune | Flexible embedding generation |
| OpenAI Embeddings API | Easy to use, great quality | API Cost | Outsourcing embedding generation |
Vector Databases and Search
Once you’ve got those embeddings, you’ll want to store and search them fast. These tools make it happen:
| Tools | Pros | Cons | Best for |
|---|---|---|---|
| Pinecone | Fully managed, scalable | Paid service | Quick, reliable vector search |
| FAISS | Open-source, very fast | Setup complexity | Self-hosted vector search |
| Weaviate | ML-enabled search | Some setup effort | Advanced vector search |
| Elasticsearch (vector plugins) | Combines keyword & vector search | Requires configuration | Hybrid search solutions |
Generative Models
This is where the AI crafts the actual responses. Some favorites include:
| Tools | Pros | Cons | Best for |
|---|---|---|---|
| Hugging Face models (LLaMA, BERT, T5) | Flexible and customizable | Resource-intensive | Customizable generation tasks |
| OpenAI GPT models | Industry-leading quality | API cost, dependency | High-quality text generation |
| Local models (Llama.cpp, vLLM) | Full control, no API costs | Hardware requirements | On-premise or privacy-focused |
Frameworks for RAG Pipelines
To tie retrieval and generation nicely, check out these handy frameworks:
| Tools | Pros | Cons | Best for |
|---|---|---|---|
| LangChain | Modular, widely used | Learning curve | Building and chaining pipeline |
| LlamaIndex | Easy data management | Newer, evolving | Managing retrieval layers |
| Haystack | Powerful, open source | Setup complexity | Full search & RAG implementations |
Infrastructure and Deployment of RAG Pipelines
Once built, your pipeline needs a home and an interface:
| Tools | Pros | Cons | Best for |
|---|---|---|---|
| AWS, GCP, Azure | Scalable cloud infrastructure | Costs | Hosting and scaling pipelines |
| FastAPI, Flask | Lightweight API frameworks | Requires development | Serving your RAG pipeline via API |
| Docker, Kubernetes | Containerization & orchestration | Learning curve | Deploying and managing services |
How to Build a RAG Pipeline?
This step-by-step guide walks you through building a complete RAG pipeline—from defining your problem to deploying a powerful, context-aware AI system.
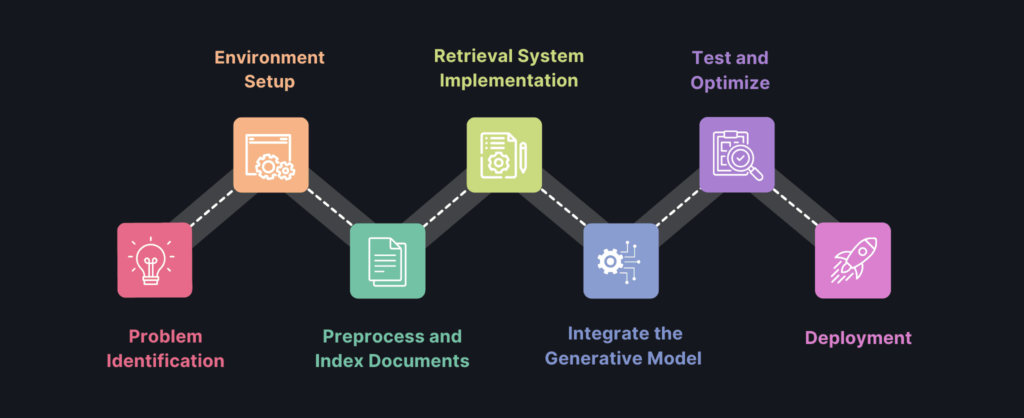
1. Identify the Problem and required Data Sources
Start by figuring out what you want your RAG pipeline to do. Are you building a customer support chatbot? A research assistant? Once you know your goal, pick the right data sources — whether that’s your company’s internal documents, public datasets, or something else.
Need help picking the right model for your industry? Check out our LLM model comparison for RAG chatbots to find the best fit.
2. Set Up the Environment
Get your workspace ready by installing the necessary libraries (e.g., pip install langchain sentence-transformers pinecone-client). You need to configure API keys if you’re using cloud services like OpenAI or Pinecone.
3. Preprocess and Index Documents
Extract the text from your documents — PDFs, web pages, or databases. Then, generate embeddings using AI models such as Sentence Transformers. These embeddings are then stored in a vector database so they’re easy to search later.
4. Implement the Retrieval System for RAG Pipelines
Create a function that converts user queries into embeddings. Use your vector database to perform similarity searches, pulling back the most relevant documents for each query.
5. Integrate the Generative Model
Pick a generative model — maybe from Hugging Face or OpenAI. Combine the retrieved documents with the user’s query to generate responses that are both context-aware and accurate. For a complete walkthrough on building an OpenAI-powered RAG chatbot, see our 2025 guide.
6. Test and Optimize RAG Pipelines
Run your pipeline with sample queries to see how it performs. Check if it retrieves relevant documents and generates quality answers. You need it to be optimized for speed, cost-efficiency, and accuracy as needed.
7. Deploy the RAG Pipeline
Set up an API endpoint to serve your RAG pipeline — frameworks like FastAPI work great here. Deploy your service on a cloud platform or your own server, and keep an eye on how it performs and scales.
Best Practices for RAG Pipelines
To get the most out of your RAG pipeline, follow these best practices that keep it accurate, efficient, and reliable over time.
- Data Quality: Make sure your data is clean, relevant, and up to date
- Embedding Optimization: Pick the right embedding model that fits your domain
- Retrieval Tuning: Tweak similarity thresholds and how many top results you pull to find the sweet spot between too many and too few answers.
- Generative Model Fine-Tuning: Fine-tune your generative model to better fit your specific use case.
- Scalability: Use batch processing, caching, and distributed setups to keep things running smoothly as your data and users grow.
- Error Handling: Have a fallback ready for when the system comes up empty — like a friendly “I didn’t find anything” message or a prompt for more info.
- Monitoring and Maintenance: Keep an eye on performance and regularly refresh your knowledge base so your pipeline stays sharp and reliable.
Looking to build a high-performing RAG pipeline or enhance your AI systems? Our AI development agency specializes in creating scalable, domain-optimized AI solutions tailored to your business.
Future Trends in RAG Pipelines
RAG pipelines are evolving fast — here’s a quick look at the exciting trends shaping their future.
- Real-Time Knowledge Updates: Pipelines should update data in a recurring process, so answers always reflect the latest data.
- Smarter Embedding Models: Expect embeddings to get faster, more efficient, and better tailored to specific industries or topics.
- Multimodal AI Integration: The future is all about mixing text, images, and videos seamlessly to deliver richer, more useful responses.
- Better Vector Databases: Look out for improvements that make searches quicker and cheaper.
- Open-Source Momentum: The community is pushing out powerful open-source RAG frameworks that make building these pipelines easier than ever.
Want to stay ahead of the curve? Hire our expert AI developers to build next-gen RAG solutions tailored to your business.
Frequently Asked Questions
RAG pipelines are advanced AI approach that blends information retrieval with text generation, allowing models to pull relevant data from trusted sources before crafting accurate, context-rich responses.
By ensuring your AI has access to the right information at the right time, RAG pipelines can dramatically improve the quality and reliability of its outputs.
If you’re ready to harness the power of RAG for your business, hire expert Python developers who can design, implement, and integrate a tailored RAG solution that meets your exact needs.
Yes. A well-architected RAG pipeline is designed to handle larger datasets over time.
If you are looking to ensure scalability, hire expert AI developers who specialize in optimizing models and retrieval layers for high-performance environments.
Let’s Talk.
Building a Retrieval-Augmented Generation (RAG) pipeline can seem complex at first, but with the right expertise, it becomes a smooth and rewarding process.
Partner with an experienced artificial intelligence development company that will guide you every step of the way — from choosing the right model and setting up your vector database to ensuring seamless integration.
Contact us!
Final words
Retrieval-Augmented Generation (RAG) pipelines are reshaping how AI delivers accurate, context-aware responses by combining the best of retrieval and generation. As the technology evolves with smarter embeddings, multimodal capabilities, and faster databases—building your own RAG pipeline is becoming more accessible and powerful than ever.
Whether you run an online store, marketplace, or retail chain, partnering with an experienced AI development company can help you implement RAG to deliver smarter recommendations, streamline operations, and boost sales.
Ready to dive in? Let’s talk
Stay Tuned for Latest Updates
Fill out the form to subscribe to our newsletter